Workflow
Deep Deformer Goal
Golaem Deep Deformer aims to replace some rig parts where the non linear deformations are costly. In such case, our deformer using deep learning technics, can learn, then replace, all the deformations, based on the inputs you will select, usually your macro rig inputs (joints, manipulators in local space, weights, etc.).
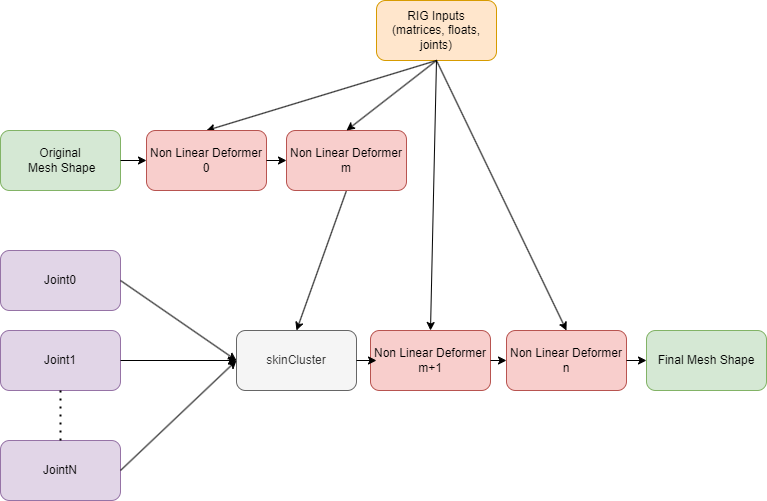
Without Golaem Deep Deformer
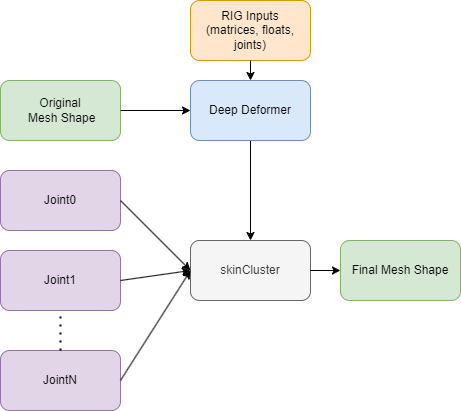
With Golaem Deep Deformer
The Deep Deformer can handle several meshes in the same model, to avoid mutiplying the models for simple assets made of numerous meshes.
Deep Deformer can also be used with the Golaem Crowd plugin, to overcome some Crowd blendshapes limitations, and bring all the RIG deformations to screen even for crowd characters.
How it works (without the math)
The deformer uses several deep learning models.
One model is in charge of learning the deformation of each vertex based on its neighbours. We call it the Differential Model. It is a heavy model that is usually trained and evaluated on GPU to save procesing time. However for really small models, or if CUDA is not available, CPU training and evaluation could be an option.
In order to work, this model needs some mesh space vertices positions as reference. Thoses are called Anchors, and by default they are only picked randomly in the vertex indices range. For each Anchor, a very small model, called subspace model, is trained to predict the absolute deformation (in mesh space) of this vertex according to rig inputs. Those models are usually trained and evaluated (infered) on CPU as they are very light.
After some math, everything is put back together at inference time, after evaluating each model.
Framework typical sequence
As each studio may have different usage, user is responsible of the model configuration and training. This is done is several steps :
- Configuration of the target mesh, and creation of its "skinCluster only", linearly deformed, mesh.
- Configuration of required RIG Inputs (joints, manipulator matrices, weights),
- Extraction of samples, made of n frames of (RIG inputs + vertices of target mesh + vertices of linear mesh)
- Training of the model
- Deployment of the model as a deformer on top of the linear mesh.